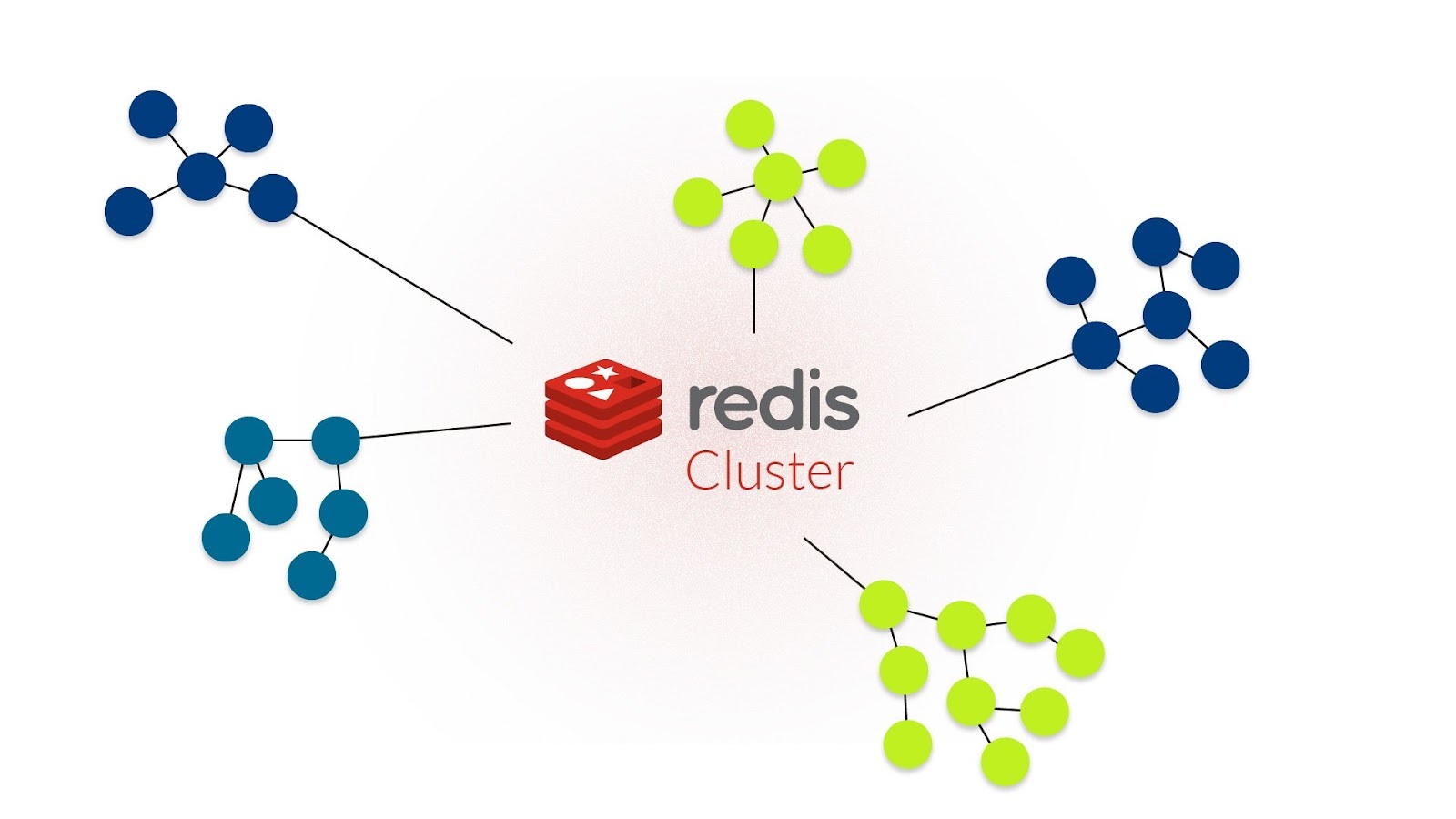
Redis Cluster FlushAll失败
温馨提示:
本文最后更新于 2023年02月01日,已超过 1,057 天没有更新。若文章内的图片失效(无法正常加载),请留言反馈或直接联系我。
问题背景
问题分析
解决方案
port 7000 //7000-7005
cluster-enabled yes //开启集群
cluster-config-file nodes.conf //保存节点配置,自动创建,自动更新
cluster-node-timeout 5000 //集群超时时间,节点超过这个时间没反应就断定是宕机
appendonly yes //存储方式,aof,将写操作记录保存到日志中 正文到此结束
热门推荐






相关文章
近期评论
-
来自: Linux 查看 占用内存最多 占用cpu最多 程序(类似top,监视)

-
来自: Quartz给任务方法传递参数
-
来自: 留言板

-
来自: 留言板

-
来自: 留言板